
We benchmarked our own tool against two general-purpose AI agents on Kyverno policy tasks. Here’s what we found, including the parts that complicate the story.
We build nctl, a CLI-based controller for Nirmata and policy as code powered by Kyverno. That means we have an obvious stake in what follows. Here’s what we did about it: we open-sourced the benchmark, used identical bare-minimum prompts across all tools, ran each tool in an isolated container with no special access, and published the dataset, evaluation code, and raw results at nirmata/policy-bench.
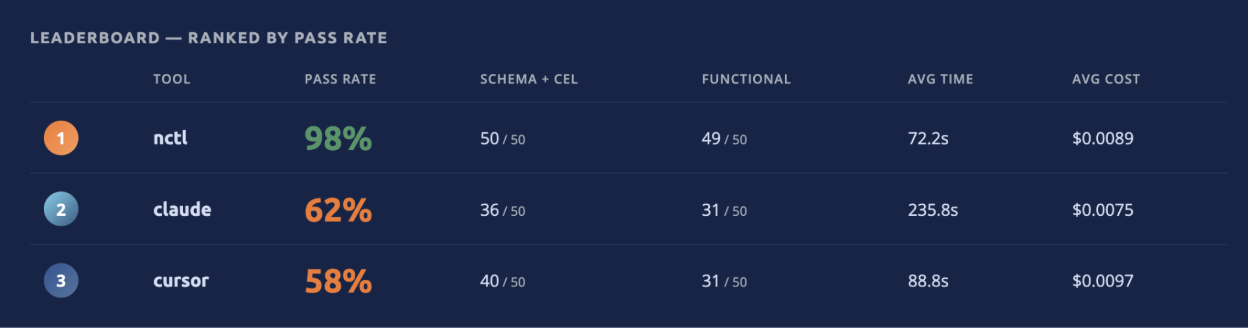
With that said, here’s the result: across 50 policy tasks using bare-minimum prompts and containerized isolation, nctl finished at 98%, Claude Code at 62%, and Cursor at 58%. Same underlying model (Claude Sonnet 4.6) in all three cases. Same prompt. Same input policies.
The gap is real. But the most interesting things we found weren’t in the headline numbers. They were in the bugs we discovered in our own benchmark along the way.
What We Were Testing
If you manage Kubernetes clusters, you deal with policy enforcement. Kyverno is one of the most widely adopted policy engines in the cloud-native ecosystem. It lets platform teams define rules like “all containers must declare resource limits” or “every namespace must have an owner label” and enforce them at admission time.
The benchmark evaluates AI tools on their ability to write and convert Kyverno policies. Each tool’s output goes through four validation layers: a kind check (is the output the right resource type?), schema and CEL validation (does the Kyverno compiler accept it?), structural linting (catches common field mistakes), and functional testing (runs kyverno test against real resource fixtures, so the policy must actually enforce the right behavior). Scoring follows SWE-bench conventions: no composite score, no arbitrary weights, just pass rate.
The conversion task is the hardest of the bunch. The expression language changes entirely (JMESPath to CEL), match criteria and mutation syntax use different schemas, Kyverno 1.16+ is recent enough that foundation models have limited training data on the new format, and the output must compile through Kyverno’s CEL engine and pass functional tests with real Kubernetes resources. Schema validity is necessary but not sufficient. A policy that compiles but rejects the wrong pods is still a failure.
The Dataset
The benchmark covers 50 tasks across multiple tracks, with every task paired to a functional test suite. No task passes on schema validity alone.
The bulk of the dataset is Cluster Policy conversion: real ClusterPolicies sourced from the kyverno/policies community library, each requiring translation to a CEL-based ValidatingPolicy, MutatingPolicy, or GeneratingPolicy. Difficulties range from simple label-checking rules to complex sidecar injection and resource generation policies.
Cluster Policy generation tasks provide plain-English descriptions (“write a policy that denies pods whose containers set privileged to true”) with no source policy to translate from. These test a different capability: writing correct policies from a specification rather than translating existing ones.
Beyond cluster policies, the benchmark now includes cross-ecosystem conversion tracks: Gatekeeper (converting OPA-based ConstraintTemplates into Kyverno ValidatingPolicies), OPA/Rego (converting standalone Rego policies), Sentinel (converting HashiCorp Sentinel policies), and Cleanup (converting Kyverno CleanupPolicies to the new DeletingPolicy type).
Dockerfile and Terraform tracks are each represented by a single task. We initially had 21 Dockerfile and 45 Terraform tasks, but trimmed to representative samples after discovering that the failures were systematic rather than task-specific (more on this below).
The benchmark also includes two separate test-generation tracks: Kyverno CLI test generation (6 tasks) and Chainsaw test generation (1 task), where the tool is given an existing policy and asked to produce a working test suite.
Results
Policy Conversion and Generation (50 tasks)
| Tool | Pass Rate | Schema + CEL | Functional | Avg Time | Avg Cost |
| nctl | 98% | 50/50 | 49/50 | 72.2s | $0.0089 |
| Claude Code | 62% | 36/50 | 31/50 | 235.8s | $0.0075 |
| Cursor | 58% | 40/50 | 31/50 | 88.8s | $0.0097 |
nctl passed schema and CEL validation on all 50 tasks and failed functional testing on just one: cp_add_ns_quota, a GeneratingPolicy that creates namespace quotas. All three tools failed that task. Claude Code and Cursor both achieved 31 functional passes but through different task subsets: Cursor passed more schema checks (40 vs. 36) but converted fewer of those into functional passes.
Kyverno CLI Test Generation (6 tasks)
| Tool | Composite Pass | Avg Coverage | Avg Time |
| nctl | 6/6 | 89% | 66.4s |
| Claude Code | 6/6 | 90% | 166.5s |
| Cursor | 4/6 | 94% | 116.3s |
All three tools performed well here. Claude Code and nctl both achieved a perfect composite pass rate. Cursor’s higher average coverage score (94%) despite fewer composite passes means it generated more test tuples per task but two of its suites didn’t actually run cleanly.
Chainsaw Test Generation (1 task)
| Tool | Composite Pass | Avg Time |
| nctl | 1/1 | 186.0s |
| Cursor | 1/1 | 274.9s |
| Claude Code | 0/1 | 600.1s |
Claude Code spent 10 minutes on this task and still didn’t produce a passing suite. Chainsaw runs tests against a live cluster simulation, making the feedback loop harder to close.
What We Found Building the Benchmark
The headline numbers tell one story. The process of getting those numbers right tells a more interesting one. Here are the findings that changed how we think about AI benchmarking.
Models hallucinate field names without schema documentation
nctl scored only 14% on Dockerfile policy tasks before we diagnosed the root cause. It wasn’t model intelligence. It was missing schema documentation. Every model (nctl, Claude Code, Cursor) made the same systematic mistakes: generating cmd.Cmd instead of cmd.Name, cmd.Args instead of cmd.CmdLine, cmd.Envs instead of cmd.Env, treating Labels and Env as maps when they’re [{Key, Value}] lists, using lowercase “run” instead of uppercase “RUN”, and omitting required has(stage.Commands) guards.
The Dockerfile resource schema for Kyverno is niche enough that no model has seen sufficient examples in training data. Without being told the schema, every model will hallucinate plausible-looking field names. This is a documentation gap, not a capability gap. Once the schema was added to nctl’s skill templates, the same policies started passing.
This finding is directly transferable: if you’re writing AGENTS.md or CLAUDE.md files for domain-specific tasks, define the target schema positively and completely. Don’t assume the model knows the field names, even if they seem obvious.
A prompt template bug was suppressing required fields
The template in nctl’s skill explicitly told the model not to include matchConstraints and validationActions for JSON-mode policies. These fields are actually required for all ValidatingPolicies regardless of evaluation mode. The bug caused structural omissions in every generated Dockerfile and Terraform policy. Once corrected, policies that had been failing validation started passing.
The lesson: when your benchmark tool is also the thing you’re benchmarking, the failure mode isn’t always in the model. Sometimes it’s in the instructions you’re giving it.
kyverno test works natively on non-Kubernetes resources
A key assumption going in was that Dockerfile and Terraform files would need a custom preprocessing layer to convert them to JSON before the Kyverno engine could evaluate them. This was wrong.
kyverno test works with custom resource types like terraform.io/v1 / kind: Plan and dockerfile.kyverno.io/v1 / kind: Dockerfile. The three Kubernetes identity fields (apiVersion, kind, metadata) are purely for the resource loader and carry no semantic meaning for CEL evaluation. The engine navigates object.planned_values.root_module.resources or object.Stages directly. Zero changes to the validator pipeline were needed.
Some tasks that appeared to pass were never testing the hard part
Two categories of false positives surfaced during validation hardening.
Tasks using resource.List() (like cp_pdb_minavailable, cp_require_pdb, cp_restrict_ingress_host) require querying live cluster resources. The old Kyverno CLI silently returned empty results for these calls; the newer CLI (v1.18.0) throws a runtime error, exposing them as untested. The policies are correct, but the test infrastructure needs cluster mocking to verify them properly.
Tasks using image.GetMetadata() (like cp_block_stale_images, cp_check_nvidia_gpu) had test data in JMESPath format from the old ClusterPolicy era. CEL-based policies need a completely different context.yaml format. The old tests were passing vacuously: the test was running, but the assertion was never exercised.
Single-run results are noisy
LLMs are nondeterministic even at temperature=0. The ch_kyverno_helm_install chainsaw task passed in one run and failed in another with identical inputs. The current headline numbers are single-run and should be taken with a grain of salt. The 36 to 40 point gap between nctl and the general-purpose agents is large enough that run-to-run variance is unlikely to change the ranking. The 4-point gap between Claude Code (62%) and Cursor (58%) is a different story: that’s two tasks, and the ordering could plausibly flip on a different run.
Reported cost is nearly meaningless
The benchmark’s cost field reports approximately $0.01 per task. The real cost per full run is significantly higher because the counter only captures the initial prompt text and output YAML, missing all intermediate tool calls, web fetches, and reasoning steps. We report the metric as-is for transparency, but it shouldn’t be used for cost comparisons between tools.
What the Gap Is Actually Made Of
The 36 to 40 percentage point gap between nctl and the general-purpose agents traces to a structural difference in where domain knowledge lives.
How we know: the prompt experiments
Before settling on the bare-minimum prompt used in the current benchmark, we ran an earlier series of experiments on a smaller cluster-policy-only dataset (41 tasks: 32 conversion, 9 generation). These experiments tested three prompt configurations to isolate where the gap comes from.
Round 1: Bare prompt. No documentation. No examples. No domain context beyond the task description itself. nctl scored 100%, Cursor 59%, Claude Code 0%.
We don’t lead with these numbers because they’re not the most informative comparison. Claude Code’s 0% had a specific cause: Kyverno 1.16+ postdates the training data, so the model produced structurally correct output (right API version, right kind) but filled the spec body with the legacy schema it knew well. That’s a predictable consequence of asking any model about a schema it hasn’t seen enough of, not a meaningful indictment of general-purpose agents. The bare prompt was useful for diagnosing where the gap came from. It wasn’t a fair race.
Round 2: Curated reference examples. We sourced before/after YAML examples directly from the kyverno-policies community repo (one pair per policy type), mounted them into the container workspace, and pointed the prompt at them. The intent was to give Claude Code and Cursor the same domain knowledge nctl’s skill provides, just in a different form.
| Tool | Bare prompt | With examples |
| nctl | 100% | 98.4% (unchanged) |
| Cursor | 59% | 76.4% (+17pp) |
| Claude Code | 0% | 73.2% (+73pp) |
Claude went from zero to 73%. nctl didn’t move. The examples gave the other tools what they were missing, but the gap didn’t close, and nctl’s immunity to the change is itself informative.
Round 3: Documentation links only. The curated examples were 331 lines of hand-picked YAML tailored to be maximally useful. That’s not how a real user would set up this task. We replaced the examples with two links (https://kyverno.io/docs/ and the community policy repo) and applied the same clause to all three tools. The agent decides how to use the docs.
This configuration produced a 97.6% / 69.1% / 68.3% split (nctl / Cursor / Claude Code). It was the most realistic apples-to-apples comparison on that dataset.
The current benchmark takes this further by stripping even the documentation links: bare-minimum prompts, no version hints, no CEL instructions, no coaching. Just “convert this ClusterPolicy to a CEL-based policy type.” This tests what the agent actually knows (or has been equipped with), not what we tell it.
Skills bridge what training data can’t
Kyverno 1.16+ is recent enough that foundation models have limited training data on the new CEL-based format. Claude Code and Cursor are working from whatever the model internalized during training, supplemented by whatever documentation they can find during execution. nctl’s converting-policies skill injects field-level mapping tables for every policy type at runtime. The model doesn’t need to locate and parse documentation; the correct schema is already in context before it starts writing.
In the bare-prompt experiment, Claude Code produced the correct output type for all 32 conversion tasks but filled the spec body with the legacy format for 22 of them. Adding documentation links closed most of that gap: Claude went from 0% to 68.3%, because the agent could now look up the correct schema rather than relying on training data alone. What documentation links couldn’t fully close: nctl’s skill injects the mapping tables on every invocation. The agent doesn’t need to find and parse the relevant docs section; the correct schema is already in context. Documentation links help, but they require the agent to locate and correctly apply the right information from a large corpus, under the same associative dynamics that caused the training data problem in the first place.
The feedback loop is a safety net, not the primary driver
nctl’s other structural advantage is its feedback loop. The skill instructs the model to run kyverno test after generating output and iterate until tests pass. In the test generation track, nctl went through three iterations on the hardest task before discovering that generation policies produce no test result for non-matching inputs. Claude Code and Cursor wrote their files and exited without running the tests. In the main conversion track, only 2 of nctl’s 50 tasks show an explicit retry in the logs, and 21 completed under 120 seconds, suggesting the skill produces correct output on the first attempt for most tasks. The feedback loop functions as a safety net for edge cases rather than the primary driver of the pass rate.
Limitations
This benchmark has an inherent conflict of interest. Nirmata built nctl. We designed the benchmark, selected the tasks, and wrote the evaluation code. We’ve made everything public and reproducible precisely because vendor-run benchmarks deserve skepticism. Run it yourself.
The results are specific to this domain. nctl has compiled skills for Kyverno policy work. A benchmark on Go refactoring, Terraform module migration, or any task where nctl has no bespoke skill would not produce the same gap. The architectural argument (that domain-specific skills, external validators, and feedback loops outperform general-purpose agents on specialized tasks) is broader than this benchmark, but this benchmark only tests one domain.
The gap may narrow as models improve. Kyverno 1.16+ is underrepresented in current training data. As more examples appear in public codebases, the advantage of a compiled skill over general model knowledge will shrink. The architectural principle (put domain knowledge in deterministic tooling, not in the model’s training data) will remain valid, but the magnitude will shift.
The current results are single-run. LLM outputs are stochastic. The nctl-vs-others gap is robust to variance, but the Claude Code vs. Cursor ordering is close enough to flip. Treat individual task outcomes as directional, not precise.
Cost data is unreliable. The cost counter undercounts real spend significantly. Don’t use the reported numbers for cost comparisons.
Try It Yourself
Dataset, prompts, evaluation code, container setup: nirmata/policy-bench.
./run-benchmark.sh --tool nctl claude cursor --containerized --persistentIf you find a flaw in the methodology or want to add tasks, pull requests are open.
nctl is the Nirmata CLI for managing Kyverno policies. nirmata.com. Live results at nirmata.github.io/policy-bench.
