
AI is changing infrastructure faster than most governance models can keep up.
That statement is bigger than model serving, bigger than copilots, and bigger than security tooling. It gets to the core operating shift now underway in enterprise infrastructure. AI workloads are moving into production on Kubernetes. Platform teams are becoming responsible not just for developer productivity, but also for security, compliance, observability, and FinOps. And AI agents are starting to accelerate the pace of change across clouds, clusters, pipelines, and configurations. The result is simple: infrastructure is now moving too fast to be governed primarily through dashboards, tickets, and after-the-fact review. CNCF’s 2025 annual survey reports that 98% of organizations now use cloud native techniques, 82% of container users run Kubernetes in production, and 66% of organizations hosting generative AI workloads use Kubernetes for that purpose.
That is why the AI era requires a different model of governance.
Not just:
Find → Report
And not even just:
Find → Fix
But:
Detect issues → Fix drift → Prevent recurrence
That is what closed-loop infrastructure governance means.
Detection is not governance
For years, infrastructure governance has largely been treated as an observability problem. Scan for misconfigurations. Flag violations. Open tickets. Generate reports for auditors. Escalate exceptions. Hope teams fix what matters.
That model was already under strain in cloud native environments. It breaks even faster in the AI era.
The CNCF survey makes an important point that often gets lost in AI hype: the real challenge is not simply model innovation, but the infrastructure needed to deploy, scale, and govern AI workloads reliably. The report says the competitive advantage lies in robust CI/CD, resource optimization, and infrastructure maturity, not just in models themselves. It also notes that 52% of organizations do not build or train models at all, which means most enterprises are not “AI labs” — they are infrastructure operators for AI-powered systems.
In other words, the AI era is making infrastructure governance more important, not less.
And when change happens at AI speed, governance that ends in a report is not governing anything. It is observing.
Why AI changes the governance model
Three things are different now.
First, AI workloads are becoming mainstream infrastructure workloads. Kubernetes is no longer just the substrate for cloud-native apps. It is increasingly the operating layer for inference, model serving, AI pipelines, and hybrid AI deployments. CNCF describes Kubernetes as the de facto orchestration layer for production AI and highlights GPU scheduling, node affinity, quotas, and deployment pipelines as critical requirements.
Second, platform teams are absorbing more governance responsibilities. The 2025 State of Platform Engineering report says platform engineering has expanded beyond DevEx and container management into AI, security, observability, and FinOps, and that the industry is moving from “shifting left” to “shifting down” by embedding controls directly into the platform.
Third, manual review does not scale to AI-driven operational velocity. The same report says 94% of organizations see AI as critical to the future of platform engineering, while 75% are already hosting or preparing to host AI workloads.
This is the real shift: AI does not just increase the need for governance. It changes the kind of governance that works.
The closed-loop model
Closed-loop infrastructure governance has three parts:
Detect issues.
Identify violations, drift, waste, or unsafe conditions across clusters, cloud resources, pipelines, and configurations.
Fix drift.
Remediate what is wrong, automatically where possible.
Prevent recurrence.
Translate what was learned into durable guardrails enforced through policy-as-code at the right control points.
That last step is the difference between a system of reporting and a system of control.
If the same class of issue can recur tomorrow, at greater scale, through the next pipeline run, cluster change, or AI-generated configuration, then governance is still reactive.
Prevention is what closes the loop.
Why prevention matters more in the AI era
In traditional environments, human review could sometimes compensate for weak controls. Teams might catch the dangerous change in code review, the over-permissive RBAC rule during audit prep, or the wasted spend when the monthly bill arrived.
That no longer works reliably when:
- AI assistants generate infrastructure configs
- AI agents propose or execute operational changes
- teams deploy faster across more environments
- GPU and inference infrastructure drives higher unit costs
- compliance scope expands across more dynamic systems
The platform engineering report is explicit here: security platform engineering is about automated guardrails and policy enforcement, secure golden paths, least-privilege access, and policy controls that manage risks, including AI agent hallucinations. It also says FinOps is shifting from detached reporting to an embedded operating model with tagging, rightsizing, lifecycle policies, and intelligent guardrails built directly into the platform.
That is a perfect description of why prevention has become strategic.
Cost governance for AI infrastructure
AI makes cost drift faster and more expensive.
For many enterprises, the bigger operational problem is not training, but inference: continuously running services, expensive accelerators, overprovisioned clusters, and inconsistent routing between APIs, GPUs, and lower-cost alternatives. CNCF notes that inference workloads run continuously, making cost management critical, and points to autoscaling, CPU-based inference for lighter workloads, GPU reservation for latency-sensitive applications, caching, retry logic, and monitoring usage and costs across providers as key practices.
A detect-only system might identify idle GPU workloads, oversized requests and limits, or unmanaged growth in API spend.
A detect-and-fix system might rightsize workloads, scale down underused resources, or clean up stale environments.
But a closed-loop system goes further. It prevents recurrence by enforcing policies such as:
- requiring resource requests and limits
- restricting GPU classes by namespace or environment
- preventing expensive instance types outside approved workloads
- enforcing cleanup and TTL policies for ephemeral environments
- mandating labels for cost allocation and ownership
That is the difference between episodic savings and durable cost governance.
Compliance governance beyond evidence collection
Compliance teams do not just need evidence. They need confidence that controls are actually enforced and that the same issues will not repeatedly resurface.
This is especially important in the AI era because infrastructure changes are more dynamic, environments are more distributed, and production systems increasingly blend applications, data access, pipelines, and model-serving infrastructure. NIST’s AI RMF and Playbook frame AI risk management as an operational discipline organized around Govern, Map, Measure, and Manage, with the Playbook offering concrete actions for implementing those outcomes.
A detect-only compliance model produces posture reports and audit snapshots.
A detect-and-fix model improves that by resolving individual findings.
But closed-loop compliance does something more valuable: it turns findings into enforceable controls.
That means if an audit discovers missing required labels, unapproved images, unsupported exceptions, or workloads that violate policy in regulated namespaces, the response is not just to clean up the current state. It is to codify the expected state as policy and enforce it going forward.
That is how organizations move from periodic compliance checking to continuous compliance state.
Security governance for RBAC and least privilege
RBAC is one of the clearest examples of why prevention matters.
The official Kubernetes RBAC good practices guide says RBAC is a key security control and emphasizes least privilege, namespace-scoped permissions where possible, and use of RoleBindings instead of ClusterRoleBindings to reduce excessive access and escalation risk.
A detect-only system might find:
- wildcard verbs
- use of cluster-admin
- broad ClusterRoleBindings
- overly permissive service accounts
- workloads running without network policy boundaries
A detect-and-fix system might clean up some of those bindings.
But in a fast-moving environment, especially one increasingly influenced by AI-generated YAML and agent-driven change, the same issue can reappear immediately unless there is prevention.
A closed-loop model prevents recurrence by enforcing policies such as:
- no wildcard verbs in RBAC rules
- blocking high-risk ClusterRoleBindings outside approved namespaces
- requiring namespace-scoped bindings by default
- disallowing privileged pods
- requiring baseline network segmentation for sensitive workloads
This is where policy-as-code becomes strategically important. It allows platform teams to convert least-privilege intent into repeatable, auditable enforcement.
From closed-loop governance to autonomous governance
At RSA, we are taking this idea one step further.
Closed-loop infrastructure governance is the right model for the AI era. But as AI systems become more autonomous, governance itself also has to evolve. It is no longer enough to find issues and hand them to humans for investigation. The system has to reason about live conditions, recommend safe fixes, enforce guardrails, and continuously verify that controls actually work.
That is the move from closed-loop governance to autonomous governance.
The problem: security controls are deployed, but rarely verified in real environments, while infrastructure is dynamic, workloads are elastic, developers move quickly, and AI-powered attacks increase the pace and complexity of risk. It is clear that “human operations cannot govern AI-speed infrastructure,” because AI agents act in seconds while human security workflows take days.
That is the agentic gap.
How Nirmata and Latent Defense bring autonomous governance to infrastructure
This is where the Nirmata and Latent Defense partnership comes in.
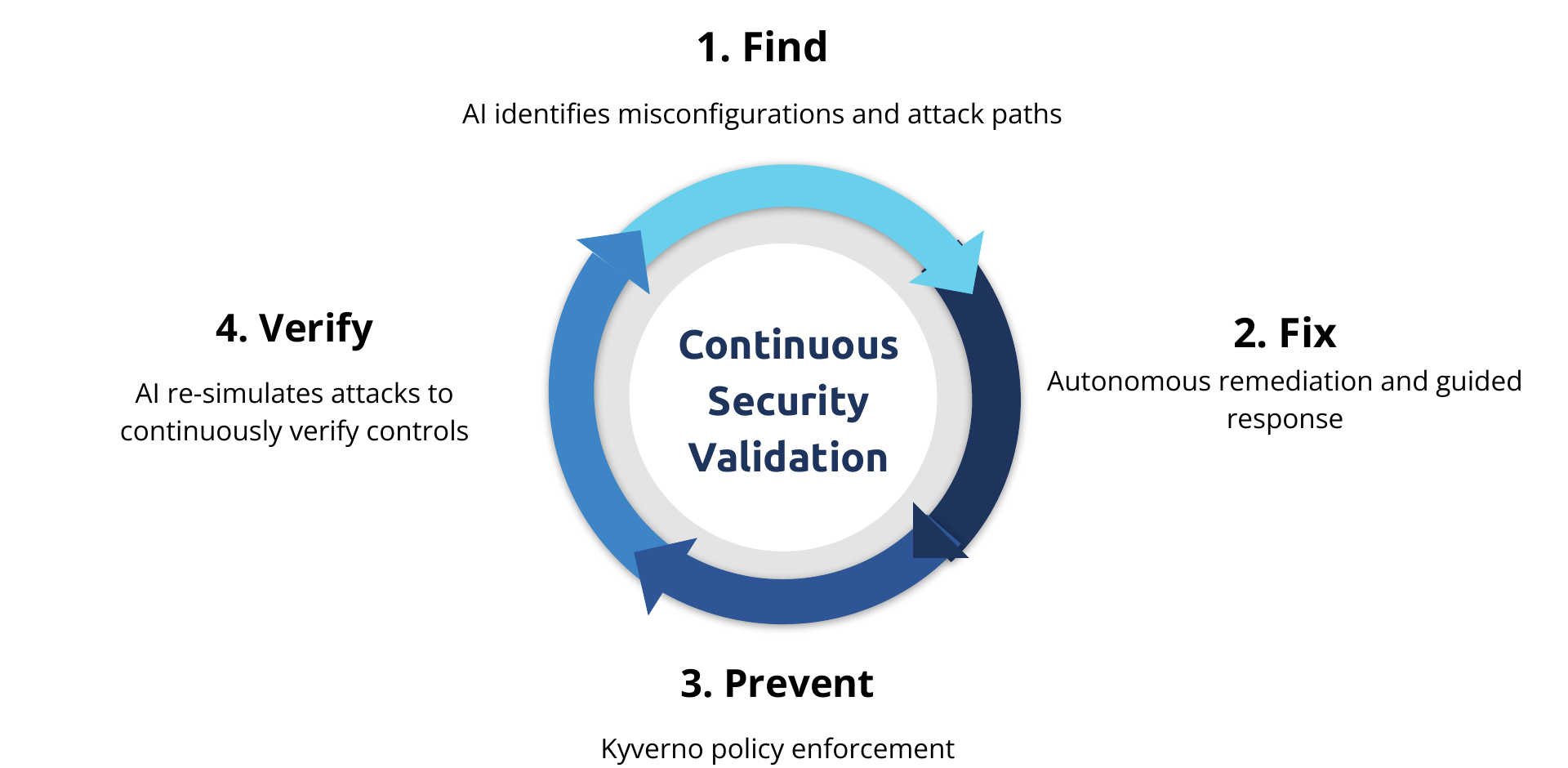
Latent Defense acts as the “brain” and Nirmata as the “muscle” of modern security. Latent Defense learns patterns, identifies vulnerabilities, detects risks, models the actual security state, runs real-time what-if scenarios, and identifies multi-step attack paths. Nirmata enforces guardrails, prevents unsafe changes, operates at admission, and provides always-on control.
Together, that creates a stronger model for infrastructure governance:
- Latent Defense finds real attack paths, not just static findings.
- Nirmata fixes and prevents by turning those insights into safe remediation and Kyverno-enforced guardrails.
- The system verifies by re-simulating attacks and validating that the controls actually stop the attack path.
That closed loop is explicit: Find, Fix, Prevent, Verify, with Kyverno policy enforcement as the preventive layer and continuous security validation at the center.
This is a meaningful step beyond traditional tooling. Compared to periodic red teaming and manual attack simulations, in this approach, AI discovers real attack paths, attempts controlled exploits, recommends fixes, enforces protections through Kyverno, and continuously revalidates after change.
For example: AI identifies an exploitable Kubernetes path involving a privileged pod, an overly permissive service account, and no network policy; Nirmata then generates and deploys a Kyverno policy to block the condition, and the system reruns the simulation to verify that the attack path is gone.
That is autonomous governance in practice:
- reason over live system state
- detect exploitable conditions
- apply safe policy-backed fixes
- continuously verify resilience
Why this matters for security leaders
This matters because security leaders are facing a new asymmetry.
Infrastructure is changing continuously. AI increases velocity. Attack paths are increasingly multi-step and contextual. And point tools rarely prove whether controls work in the live environment.
The Nirmata solution brief already frames Nirmata as an AI platform engineering assistant that turns policy-as-code into automated governance for security, compliance, cost, and reliability, with agents that work together to close the loop from detection to remediation to enforcement. It also highlights lower costs through utilization enforcement and cleanup policies, standardized compliance, and faster resolution with AI remediation agents.
That is exactly the operating model security teams need now:
- not more fragmented findings
- not more tickets
- not just more remediation advice
- but a system that can turn intent into enforced behavior
The new standard: governance as control, not observation
This is the category shift.
Infrastructure governance used to be largely about visibility:
- What changed?
- What drifted?
- What violated policy?
- What should be reviewed?
In the AI era, that is no longer enough.
The new standard is:
- detect what matters
- fix what drifted
- prevent the same class of problem from coming back
- verify continuously that controls still work
That is how platform and security teams reduce toil, lower risk, improve compliance posture, contain cost, and keep AI-era infrastructure within safe operating boundaries.
The AI era requires closed-loop infrastructure governance: detect issues, fix drift, and prevent recurrence.
And the next step is autonomous governance: systems that can find, fix, prevent, and verify at machine speed.
See it live at RSA
At RSA, Nirmata and Latent Defense are showing what this looks like in practice: autonomous governance for Kubernetes and modern infrastructure, combining AI-powered attack path discovery with Kyverno-backed policy enforcement and continuous verification. The goal is simple: governance that scales with compute, not headcount, with faster resolution, always-audit-ready compliance, and stronger security posture.
Call to action: prove it in 2 hours
If you want to see whether your Kubernetes environment already contains exploitable attack paths, we’re offering a 2-Hour Autonomous Kubernetes Security Proof. Our assessment includes AI-driven attack path discovery against real cluster conditions and policies, with clear remediation steps and validation.
See the offer here: 2-Hour Cluster Scan Proof
